

Lettre D
DÉNOMBRABLE
Un ensemble  est qualifié de dénombrable, par définition, lorsqu’il existe une bijection
est qualifié de dénombrable, par définition, lorsqu’il existe une bijection  Bien entendu, dès qu’une telle bijection existe, on dispose de sa réciproque
Bien entendu, dès qu’une telle bijection existe, on dispose de sa réciproque  On peut donc reformuler : est dit dénombrable tout ensemble « en bijection avec
On peut donc reformuler : est dit dénombrable tout ensemble « en bijection avec  » .
» .
On peut montrer que chacun des ensembles suivants est dénombrable : 

 et
et 
Pour  , c’est facile à justifier : l’application
, c’est facile à justifier : l’application  est bijective.
est bijective.
Cet exemple se généralise : si  est une partie finie de alors l’ensemble
est une partie finie de alors l’ensemble  (lire : privé de
(lire : privé de  qui est par définition constitué des entiers naturels qui n’appartiennent pas à
qui est par définition constitué des entiers naturels qui n’appartiennent pas à  est dénombrable.
est dénombrable.
Pour c’est un peu moins évident : on s’en sort en énumérant les entiers relatifs « en zig-zag » . Autrement dit : 0, 1, -1, 2, -2, 3, -3, etc … Cette peut être formalisée en considérant l’application
![\[\mathbb{N}\rightarrow\mathbb{Z},\thinspace n\mapsto\left\{ \begin{array}{cc}-n/2 & \text{si }n\text{ est pair}\\\left(n+1\right)/2 & \text{si }n\text{ est impair}\end{array}\right.\]](https://math-os.com/wp-content/ql-cache/quicklatex.com-1c1e9580c49c10f7fea455cf0f6a096e_l3.png "Rendered by QuickLaTeX.com")
En revanche  n’est pas dénombrable. Une preuve de cette affirmation est donnée dans cet article de vulgarisation et vous pourrez suivre, dans la vidéo ci-dessous, pas moins de quatre preuve de ce résultat :
n’est pas dénombrable. Une preuve de cette affirmation est donnée dans cet article de vulgarisation et vous pourrez suivre, dans la vidéo ci-dessous, pas moins de quatre preuve de ce résultat :
Etant donné est un ensemble , il n’existe aucune surjection (et, en particulier, aucune bijection) de vers  . On voit ainsi que
. On voit ainsi que  est non dénombrable.
est non dénombrable.
La proposition suivante est fondamentale : si  est une suite d’ensembles dénombrables, alors
est une suite d’ensembles dénombrables, alors  est aussi dénombrable.
est aussi dénombrable.
Les challenges numéros 34, 49 et 73 entrent plus ou moins dans cette thématique. Vous êtes invité(e) à y réfléchir.
DENSE (partie)
Définition
Soient  un espace vectoriel normé et soit
un espace vectoriel normé et soit  On dit que est dense dans lorsque tout vecteur de est la limite d’une suite convergente à termes dans
On dit que est dense dans lorsque tout vecteur de est la limite d’une suite convergente à termes dans 
Remarque
Cette définition est présentée ainsi par souci de simplicité. Une version à la fois plus générale et plus officielle serait la suivante :
Soit un espace topologique et soit  On dit que est dense dans lorsque
On dit que est dense dans lorsque  (le symbole
(le symbole  désigne l’adhérence de dans
désigne l’adhérence de dans 
Si la topologie de est métrisable (c’est-à-dire : s’il existe une distance  sur qui induit sa topologie), cette condition équivaut à l’existence, pour tout
sur qui induit sa topologie), cette condition équivaut à l’existence, pour tout  d’une suite
d’une suite  à termes dans qui converge vers
à termes dans qui converge vers  c’est-à-dire telle que :
c’est-à-dire telle que :
![\[ \lim_{n\rightarrow\infty}d\left(x,a_{n}\right)=0\]](https://math-os.com/wp-content/ql-cache/quicklatex.com-93dc13d8e8c73da1808e6ede72c6c686_l3.png "Rendered by QuickLaTeX.com")
![\[\forall\left(x,y\right)\in E^{2},\thinspace d\left(x,y\right)=\left\Vert x-y\right\Vert\]](https://math-os.com/wp-content/ql-cache/quicklatex.com-c63ee689c250c29acbc066ed7c6bd3d3_l3.png "Rendered by QuickLaTeX.com")
, étant données deux parties  de telles que
de telles que  on dit que est dense dans
on dit que est dense dans  lorsque
lorsque  . Attention : à moins de supposer que est un fermé de , il n’y a pas de raison que l’inclusion réciproque soit vraie.
. Attention : à moins de supposer que est un fermé de , il n’y a pas de raison que l’inclusion réciproque soit vraie.
Exemple 1
Dans les parties suivantes sont denses :
- l’ensemble
 des rationnels
des rationnels - l’ensemble
 des irrationnels
des irrationnels
Exemple 2
Dans  les parties suivantes sont denses :
les parties suivantes sont denses :
- l’ensemble des matrice inversibles (qui est aussi un ouvert)
- l’ensemble des matrices diagonalisables

L’un des principaux intérêts de la notion de densité le suivant : pour démontrer une propriété donnée pour chaque élément d’un certain espace, il suffit parfois de l’établir pour les éléments d’une partie dense, puis de passer à la limite.
Voici quelques illustrations de cette idée :
- Si
 est continue et si
est continue et si  pour tout
pour tout  alors
alors 
- Si
![f\in\mathcal{C}\left(\left[0,1\right],\mathbb{R}\right)](https://math-os.com/wp-content/ql-cache/quicklatex.com-15f480ea4c0175622898313d0aa46f05_l3.png "Rendered by QuickLaTeX.com") vérifie
vérifie  pour tout
pour tout  alors On peut voir (par linéarité) que
alors On peut voir (par linéarité) que  pour toute fonction polynomiale
pour toute fonction polynomiale  puis raisonner par densité grâce au théorème d’approximation uniforme de Weierstrass.
puis raisonner par densité grâce au théorème d’approximation uniforme de Weierstrass. - Si
 alors
alors  On peut d’abord le prouver pour les couples de matrices inversibles, puis utiliser la continuité de l’application
On peut d’abord le prouver pour les couples de matrices inversibles, puis utiliser la continuité de l’application  et le fait que
et le fait que  est une partie dense de
est une partie dense de 
- Si
 alors
alors  On peut prouver cela pour les matrices diagonalisables (qui forment une partie dense de
On peut prouver cela pour les matrices diagonalisables (qui forment une partie dense de  ), puis invoquer la continuité du déterminant, de l’exponentielle (complexe et matricielle) et de la trace.
), puis invoquer la continuité du déterminant, de l’exponentielle (complexe et matricielle) et de la trace.
DIAGONALISABLE
Soit un  espace vectoriel de dimension finie et soit
espace vectoriel de dimension finie et soit 
Définition 1
 est dit diagonalisable lorsqu’il existe une base de formée de vecteurs propres pour
est dit diagonalisable lorsqu’il existe une base de formée de vecteurs propres pour  Dans une telle base, est représenté par une matrice diagonale, d’où la terminologie.
Dans une telle base, est représenté par une matrice diagonale, d’où la terminologie.
Définition 2
Une matrice  est dite diagonalisable dans
est dite diagonalisable dans  (précision indispensable ! voir exemple ci-dessous) lorsque l’endomorphisme de
(précision indispensable ! voir exemple ci-dessous) lorsque l’endomorphisme de  canoniquement associé à
canoniquement associé à  est diagonalisable.
est diagonalisable.
Ceci revient à dire qu’il existe un couple  tel que :
tel que :
![\[P\text{ est inversible}\qquad\Delta\text{ est diagonale}\qquad P\Delta P^{-1}=M\]](https://math-os.com/wp-content/ql-cache/quicklatex.com-2555158ab7cb58044786a75432e291f1_l3.png "Rendered by QuickLaTeX.com")
Exemple
![\left[\begin{array}{cc}0 & -1\\1 & 0\end{array}\right]](https://math-os.com/wp-content/ql-cache/quicklatex.com-5678c2276183d95902401baf141183d6_l3.png "Rendered by QuickLaTeX.com") est diagonalisable dans
est diagonalisable dans  mais pas dans
mais pas dans 
On note  le spectre de et
le spectre de et  son polynôme caractéristique.
son polynôme caractéristique.
Pour chaque valeur propre  on note :
on note :
 la dimension du sous-espace propre associé
la dimension du sous-espace propre associé la multiplicité de
la multiplicité de  en tant que racine de
en tant que racine de
Théorème 1
est diagonalisable si, et seulement si, est scindé dans ![\mathbb{K}\left[X\right]](https://math-os.com/wp-content/ql-cache/quicklatex.com-df93be377a36375414a904d2b1b50708_l3.png "Rendered by QuickLaTeX.com") et de plus :
et de plus :
![\[ \forall\lambda\in\text{sp}\left(u\right),\thinspace d\left(\lambda\right)=m\left(\lambda\right) \]](https://math-os.com/wp-content/ql-cache/quicklatex.com-b9f4e5b489f485ebe4d19cac600ca098_l3.png "Rendered by QuickLaTeX.com")
Corollaire
Si est scindé dans et à racines simples, alors est diagonalisable.
Par exemple, l’endomorphisme de  canoniquement associé à la matrice triangulaire
canoniquement associé à la matrice triangulaire
![\[A=\left[\begin{array}{cccc}0 & 1 & 1 & 1\\0 & 1 & 1 & 1\\0 & 0 & 2 & 1\\0 & 0 & 0 & 3\end{array}\right]\]](https://math-os.com/wp-content/ql-cache/quicklatex.com-5956ab1be6bb931beaf7b71d307b595f_l3.png "Rendered by QuickLaTeX.com")
Autre exemple, moins immédiat : toute matrice  est la limite d’une suite de matrices diagonalisables dans . Autrement dit, l’ensemble des matrices diagonalisables dans est une partie dense de .
est la limite d’une suite de matrices diagonalisables dans . Autrement dit, l’ensemble des matrices diagonalisables dans est une partie dense de .

Attention : Le corollaire ci-dessus ne donne qu’une condition suffisante (et pas du tout nécessaire) de diagonalisation. Par exemple, une homothétie est évidemment diagonalisable et possède pourtant une valeur propre multiple (en dimension  ).
).
Théorème 2
est diagonalisable si, et seulement s’il existe ![P\in\mathbb{K}\left[X\right],](https://math-os.com/wp-content/ql-cache/quicklatex.com-410e046c93be39a0ab865de9b5217892_l3.png "Rendered by QuickLaTeX.com") scindé dans et à racines simples, tel que
scindé dans et à racines simples, tel que 
Par exemple : tout projecteur de est diagonalisable puisqu’annulé par  de même (en caractéristique différente de 2) toute symétrie de est diagonalisable puisqu’annulée par
de même (en caractéristique différente de 2) toute symétrie de est diagonalisable puisqu’annulée par 
DISTANCE (à une partie)
Définition
Soient un espace vectoriel normé et une partie non vide  .
.
Pour tout  , on note :
, on note :
![\[d\left(x,A\right)=\inf\left\{ \left\Vert x-a\right\Vert ;\thinspace a\in A\right\}\]](https://math-os.com/wp-content/ql-cache/quicklatex.com-ee940f7bd9c2798ad8eb5f1c83b81d91_l3.png "Rendered by QuickLaTeX.com")
 à la partie
à la partie
Remarque
Cette définition s’étend naturellement aux espaces métriques, en remplaçant  par la distance entre et
par la distance entre et 
Exemple 1
Dans  si
si  , alors pour tout
, alors pour tout  :
:
![\[d\left(x,\left]a,b\right[\right)=\left\{ \begin{array}{cc}a-x & \text{si }x < a\\0 & \text{si }a\leqslant x \leqslant b\\x-b & \text{si }x > b\end{array}\right.\]](https://math-os.com/wp-content/ql-cache/quicklatex.com-4a0ca53b2dcaf4ffd4f4907c2b668ad5_l3.png "Rendered by QuickLaTeX.com")
Exemple 2
Dans  muni de sa norme euclidienne, considérons
muni de sa norme euclidienne, considérons  et
et  et notons
et notons  le disque fermé de centre
le disque fermé de centre  et de rayon
et de rayon  Alors, pour tout
Alors, pour tout  , en notant :
, en notant :
![\[\rho=\sqrt{\left(x-a\right)^{2}+\left(y-b\right)^{2}}\]](https://math-os.com/wp-content/ql-cache/quicklatex.com-a9c57a207d55d9f9b66553d4957b64dc_l3.png "Rendered by QuickLaTeX.com")
![\[d\left(\left(x,y\right),D\right)=\left\{ \begin{array}{cc}0 & \text{si }\rho\leqslant r\\\sqrt{\left(x-a\right)^{2}+\left(y-b\right)^{2}}-r & \text{sinon}\end{array}\right.\]](https://math-os.com/wp-content/ql-cache/quicklatex.com-c80742fa4cf55a2f79ed3004ac9eff68_l3.png "Rendered by QuickLaTeX.com")
Dans l’illustration ci-dessous, est l’union de trois ellipses.
Pour certains points, la distance à est atteinte une fois, pour d’autres deux fois. Il existe même deux points pour lesquelles elle est atteinte trois fois (on pourrait qualifier ces points de points triples) : l’un d’eux a été représenté; sauriez-vous localiser l’autre ?
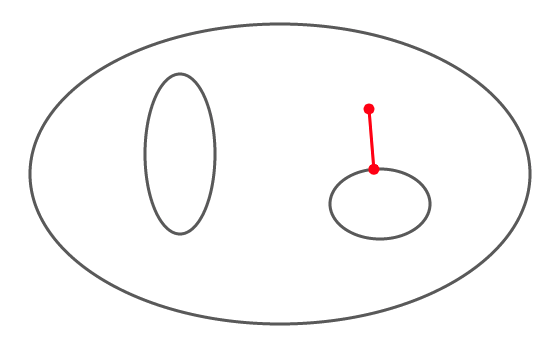
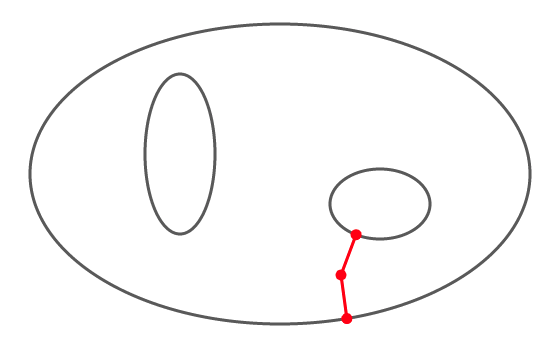
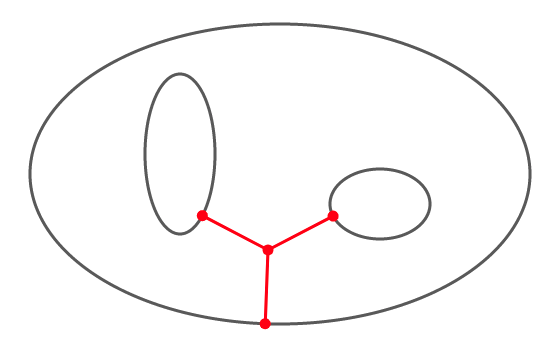
Voici quelques résultats de base, à connaître …
1 – Vecteurs à distance nulle. D’une manière générale :
![\[d\left(x,A\right)=0\Leftrightarrow x\in\overline{A}\]](https://math-os.com/wp-content/ql-cache/quicklatex.com-f6b9f5d1ef3d92d462cbb7ec7e7b330a_l3.png "Rendered by QuickLaTeX.com")
désigne l’adhérence de
En particulier, si est fermé alors les vecteurs qui sont à distance nulle de sont exactement les éléments de
Sans cette hypothèse, il reste que  mais l’implication réciproque est fausse. Par exemple, dans :
mais l’implication réciproque est fausse. Par exemple, dans :
![\[d\left(0,\left]0,1\right]\right)=0\quad\text{bien que } 0\notin\left]0,1\right]\]](https://math-os.com/wp-content/ql-cache/quicklatex.com-2290f65c76a98e5fcb0922dbe7ee1f4f_l3.png "Rendered by QuickLaTeX.com")
2 – Continuité. On peut montrer que l’application
![\[d_{A}:E\rightarrow\mathbb{R},\thinspace x\mapsto d\left(x,A\right)\]](https://math-os.com/wp-content/ql-cache/quicklatex.com-25833d0e258eff84c7e2fb35f9cb483d_l3.png "Rendered by QuickLaTeX.com")
![\[\forall\left(x,y\right)\in E^{2},\thinspace\left|d\left(x,A\right)-d\left(y,A\right)\right|\leqslant\left\Vert x-y\right\Vert\]](https://math-os.com/wp-content/ql-cache/quicklatex.com-da62edfdf5d18f4a609cc43b478c2cb5_l3.png "Rendered by QuickLaTeX.com")

On peut s’interroger sur la différentiabilité de  , mais c’est une question plus délicate, qui fait intervenir les propriétés géométriques et topologiques de
, mais c’est une question plus délicate, qui fait intervenir les propriétés géométriques et topologiques de
3 – Distance atteinte. Si  est un compact de alors (propriété générale d’une application continue sur un compact et à valeurs réelles), pour tout
est un compact de alors (propriété générale d’une application continue sur un compact et à valeurs réelles), pour tout  il existe
il existe  tel que :
tel que :
![\[\left\Vert x-k\right\Vert =d\left(x,K\right)\]](https://math-os.com/wp-content/ql-cache/quicklatex.com-02f5bc7bb920d21d0e169dd6b062ece7_l3.png "Rendered by QuickLaTeX.com")
 n’est pas unique : penser à un cercle
n’est pas unique : penser à un cercle  du plan euclidien et son centre
du plan euclidien et son centre  … la distance de à
… la distance de à  qui est bien sûr égale au rayon, est atteinte une infinité de fois (en tout point de
qui est bien sûr égale au rayon, est atteinte une infinité de fois (en tout point de 
Et sans hypothèse de compacité, l’existence d’un tel n’est pas assurée : considérer cette fois un disque ouvert de centre et de rayon  ainsi qu’un point extérieur à
ainsi qu’un point extérieur à  Alors
Alors  et cette distance n’est pas atteinte.
et cette distance n’est pas atteinte.
4 – Projection orthogonale. Dans le cadre des espaces préhilbertiens, le théorème de la projection orthogonale donne des informations sur la distance d’un vecteur à un sous-espace de dimension finie (ou, plus généralement, à une partie non vide, convexe et complète). Voir cet article.
DUPLICATION (trigonométrie)
En trigonométrie circulaire, les formules :
(1) ![\[\boxed{\sin\left(2\theta\right)=2\sin\left(\theta\right)\cos\left(\theta\right)}\]](https://math-os.com/wp-content/ql-cache/quicklatex.com-2b0d5ab9ea760efa443515d458a4f2eb_l3.png "Rendered by QuickLaTeX.com")
(2) ![\[\boxed{\cos\left(2\theta\right)=\cos^{2}\left(\theta\right)-\sin^{2}\left(\theta\right)}\]](https://math-os.com/wp-content/ql-cache/quicklatex.com-b4e2783dd469f12feed8158847402583_l3.png "Rendered by QuickLaTeX.com")
 . Elles doivent leur nom au fait qu’elles permettent de relier les lignes trigonométriques d’un angle à celles de l’angle double (ou de l’angle moitié, selon le point de vue …).
. Elles doivent leur nom au fait qu’elles permettent de relier les lignes trigonométriques d’un angle à celles de l’angle double (ou de l’angle moitié, selon le point de vue …).
Grâce à la formule fondamentale  la relation
la relation  peut encore s’écrire :
peut encore s’écrire :


![\[\cos^{2}\left(\theta\right)=\frac{1+\cos\left(2\theta\right)}{2}\]](https://math-os.com/wp-content/ql-cache/quicklatex.com-121846012c71e9c63cb7f9180975b2b4_l3.png "Rendered by QuickLaTeX.com")
![\[\sin^{2}\left(\theta\right)=\frac{1-\cos\left(2\theta\right)}{2}\]](https://math-os.com/wp-content/ql-cache/quicklatex.com-aba4a8a0d82095eef4c9ef9df30b9720_l3.png "Rendered by QuickLaTeX.com")
 et on obtient la formule de duplication pour la fonction tangente :
et on obtient la formule de duplication pour la fonction tangente : ![\[\tan\left(2\theta\right)=\frac{2\tan\left(\theta\right)}{1-\tan^{2}\left(\theta\right)}\]](https://math-os.com/wp-content/ql-cache/quicklatex.com-a6a1b8bdf8e1b9977a5a172e370932ad_l3.png "Rendered by QuickLaTeX.com")
 avec :
avec : ![\[D=\left\{ \frac{k\pi}{4};\thinspace k\in\mathbb{Z}\text{ et }k\equiv1,2\text{ ou }3\pmod{4}\right\}\]](https://math-os.com/wp-content/ql-cache/quicklatex.com-6c72fc64f49786bc585975c2a7ed3a1b_l3.png "Rendered by QuickLaTeX.com")
On a essentiellement la même chose en trigonométrie hyperbolique. En effet, pour tout :
(1′) ![\[\boxed{\sinh\left(2x\right)=2\sinh\left(x\right)\cosh\left(x\right)}\]](https://math-os.com/wp-content/ql-cache/quicklatex.com-f30bca74646ef06636bd5760e771d6b8_l3.png "Rendered by QuickLaTeX.com")
(2′) ![\[\boxed{\cosh\left(2x\right)=\cosh^{2}\left(x\right)+\sinh^{2}\left(x\right)}\]](https://math-os.com/wp-content/ql-cache/quicklatex.com-89739a6b5fff498809a8764a9b80a7e2_l3.png "Rendered by QuickLaTeX.com")
 permet de reformuler
permet de reformuler  :
: ![\[\cosh\left(2x\right)=2\cosh^{2}\left(x\right)-1\]](https://math-os.com/wp-content/ql-cache/quicklatex.com-8a9d877690a9e95044258d0c4eb97875_l3.png "Rendered by QuickLaTeX.com")
![\[\cosh\left(2x\right)=1+2\sinh^{2}\left(x\right)\]](https://math-os.com/wp-content/ql-cache/quicklatex.com-b32bf19192f04aacfdba206a93be4d02_l3.png "Rendered by QuickLaTeX.com")
![\[\cosh^{2}\left(x\right)=\frac{1+\cosh\left(2x\right)}{2}\]](https://math-os.com/wp-content/ql-cache/quicklatex.com-98ea2ad6be1cca44967934f67b7558aa_l3.png "Rendered by QuickLaTeX.com")
![\[\sinh^{2}\left(x\right)=\frac{\cosh\left(2x\right)-1}{2}\]](https://math-os.com/wp-content/ql-cache/quicklatex.com-b212e09641d144d08330d5fa8f501e8e_l3.png "Rendered by QuickLaTeX.com")
 et
et  on obtient la formule de duplication pour la tangente hyperbolique :
on obtient la formule de duplication pour la tangente hyperbolique : ![\[\tanh\left(2x\right)=\frac{2\tanh\left(x\right)}{1+\tanh^{2}\left(x\right)}\]](https://math-os.com/wp-content/ql-cache/quicklatex.com-0b827b8d335cf6ebdb264a3522a7849b_l3.png "Rendered by QuickLaTeX.com")
